Virtual Machine Flavors Optimized for Parallel Workloads
In this article
- Summary
- NUMA-aware scheduling
- CPU pinning
- Zero oversubscription
- Flavors designed for parallel workloads
Summary
Hyperstack's latest flavors configured with x4 or x8 GPUs, introduce NUMA-aware scheduling and dedicated pinning for CPUs and Memory. Virtual machines equipped with these features have demonstrated up to a 50% improvement in performance for parallel workloads, as reported by some of our enhancements empower users to execute parallel workloads on the same virtual machine without compromising performance due to overhead and slower communication across distinct NUMA zones.
Generation N2 and N3 flavors, featuring x4 or x8 GPUs, include the following features tailored to enhance performance for parallel workloads:
-
NUMA-aware scheduling, aligning the compute resources of the virtual machine (CPUs, memory, GPUs, network devices, local storage) in the same NUMA zone to process latency-sensitive and high-performance workloads efficiently.
-
Physical CPU pinning to eliminate context switching latency and noisy neighbor effects on virtual machines.
-
All our virtual machine flavors are dedicated and adhere to a 1:1 mapping with physical resources, ensuring optimal performance without oversubscription.
For example, a virtual machine with the x8 GPU N2/N3 flavor, which is NUMA-aware and supports CPU pinning, can efficiently run Workload X on GPUs 0-3 and Workload Y on GPUs 4-7 simultaneously without any loss in performance.
Flavors equipped with x1 or x2 GPUs are not NUMA-aware and do not feature CPU pinning, making them suboptimal for parallel workloads. To explore all flavors with NUMA-awareness and CPU pinning, click here.
To learn more about NUMA-aware scheduling, CPU pinning, zero oversubscription, and to explore a list of flavors offering these features, read more about these capabilities below.
NUMA-aware scheduling
Non-Uniform Memory Access (NUMA) is a computing platform architecture that allows different CPUs to access different regions of memory at varying speeds. NUMA resource topology refers to the locations of CPUs, memory, and PCI devices (GPUs, network cards, local storage) relative to each other in the compute node. Resources situated in the same NUMA zone are considered co-located. For high-performance applications, the virtual machine needs to process workloads in a single NUMA zone.
NUMA architecture allows a CPU with multiple memory controllers to use any available memory across CPU complexes, regardless of where the memory is located. This allows for increased flexibility at the expense of performance. A CPU processing a workload using memory that is outside its NUMA zone is slower than a workload processed in a single NUMA zone. Also, for I/O-constrained workloads, the network interface on a distant NUMA zone slows down how quickly information can reach the application. High-performance workloads, such as AI/ML workloads, cannot operate to specification under these conditions. NUMA-aware scheduling aligns the requested cluster compute resources (CPUs, memory, GPUs, network devices, local storage) in the same NUMA zone to process latency-sensitive or high-performance workloads efficiently.
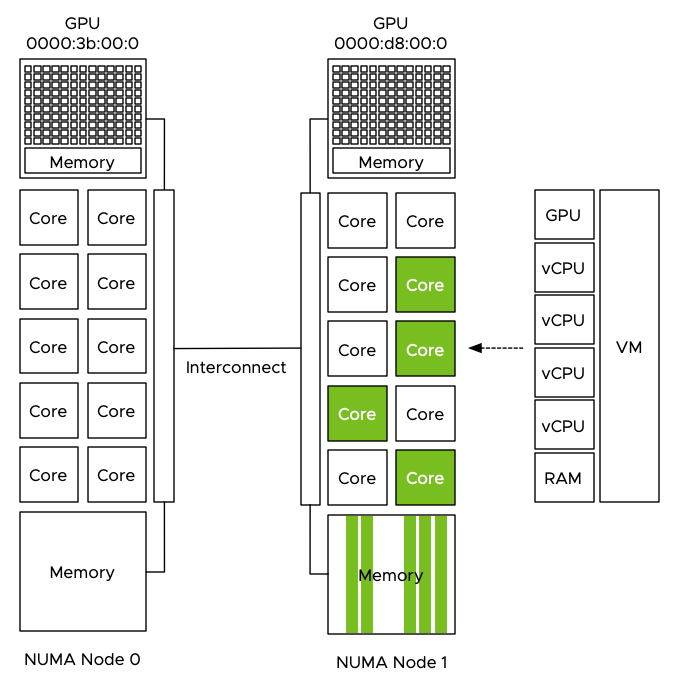
For optimal performance, the NUMA scheduler ensures the data is stored in the local memory of the processor where the CPUs are running. In this example above, the CPUs of the VM are scheduled on the cores of CPU 1 (NUMA node 1). Consequently, the NUMA scheduler directs the VM kernel memory scheduler to store data in the memory managed by the memory controllers of CPU 1.
CPU pinning
When running a guest operating system in a virtual machine, two NUMA topologies are involved: that of the physical hardware of the host and that of the virtual hardware exposed to the guest operating system. The host operating system and associated utilities are aware of the host’s NUMA topology and will optimize accordingly, but by exposing a NUMA topology to the guest that aligns with that of the physical hardware it is running on, we can also assist the guest operating system to do the same.
In addition to the NUMA-aware scheduling enabled for the x4 and x8 GPU flavors, we also implement dedicated CPU pinning. This establishes a 1:1 mapping, ensuring each host CPU is dedicated and pinned to the corresponding guest CPU. This approach eliminates latency caused by CPU context switching, where virtual CPU cores in the guest are randomly mapped to different physical CPU cores on the host. Additionally, it eliminates noisy neighbor effects, preventing other VMs on the same host from sharing physical cores with your VM and potentially diminishing overall performance.
Zero oversubscription
All infrastructure resources, including GPUs, CPUs, Memory, and Storage, from Hyperstack maintain a 1:1 mapping or allocation ratio to the physical resources on their bare-metal hosts. In contrast to many cloud providers, we do not oversubscribe our resources, ensuring you experience optimal performance with Hyperstack virtual machines.
Flavors designed for parallel workloads
The following flavors, equipped with x4 or x8 GPUs, include NUMA-aware scheduling and dedicated pinning for CPUs and Memory. These features enable customers to execute parallel workloads on the same virtual machine without compromising performance.
L40
GPU: L40-48GB-PCIe
| Flavor Name | GPU Count | CPU Cores | RAM (GB) | Root Disk (GB) | Ephemeral Disk (GB) | NUMA Node Pinning | CPU Pinning |
|---|---|---|---|---|---|---|---|
n3-L40x4 | 4 | 124 | 232 | 100 | 3200 | Yes | Yes |
n3-L40x8 | 8 | 252 | 464 | 100 | 6500 | Yes | Yes |
A100
GPU: A100-80GB-PCIe
| Flavor Name | GPU Count | CPU Cores | RAM (GB) | Root Disk (GB) | Ephemeral Disk (GB) | CPU Pinning | NUMA Node Pinning |
|---|---|---|---|---|---|---|---|
n3-A100x4 | 4 | 124 | 480 | 100 | 3200 | Yes | Yes |
n3-A100x8 | 8 | 252 | 1440 | 100 | 6500 | Yes | Yes |
GPU: A100-80GB-PCIe w/ NVLink *
| Flavor Name | GPU Count | CPU Cores | RAM (GB) | Root Disk (GB) | Ephemeral Disk (GB) | CPU Pinning | NUMA Node Pinning |
|---|---|---|---|---|---|---|---|
n2-A100x8-NVLink-v2 | 8 | 252 | 1920 | 100 | 6500 | Yes | Yes |
***** The n2-A100x8-NVLink-v2 flavor is exclusively available for contracted customers.
H100
GPU: H100-80GB-PCIe
| Flavor Name | GPU Count | CPU Cores | RAM (GB) | Root Disk (GB) | Ephemeral Disk (GB) | CPU Pinning | NUMA Node Pinning |
|---|---|---|---|---|---|---|---|
n3-H100x4 | 4 | 124 | 720 | 100 | 3200 | Yes | Yes |
n3-H100x8 | 8 | 252 | 1440 | 100 | 6500 | Yes | Yes |
GPU: H100-80G-PCIe-NVLink
| Flavor Name | GPU Count | CPU Cores | RAM (GB) | Root Disk (GB) | Ephemeral Disk (GB) | CPU Pinning | NUMA Node Pinning |
|---|---|---|---|---|---|---|---|
n3-H100x8-NVLink | 8 | 252 | 1440 | 100 | 6500 | Yes | Yes |